可以用通常的 histogram 进行时间分析吗?
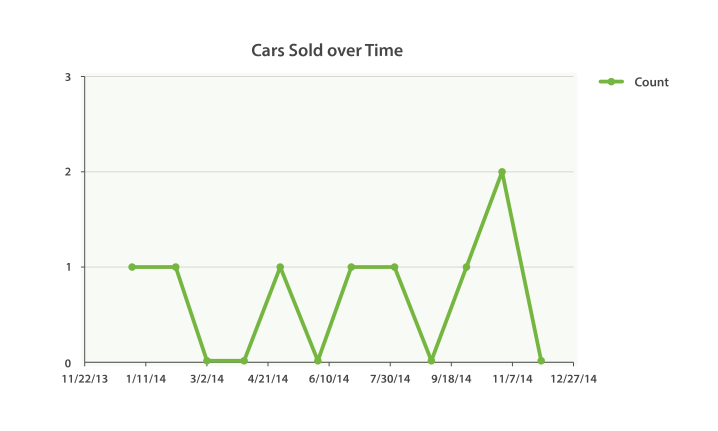
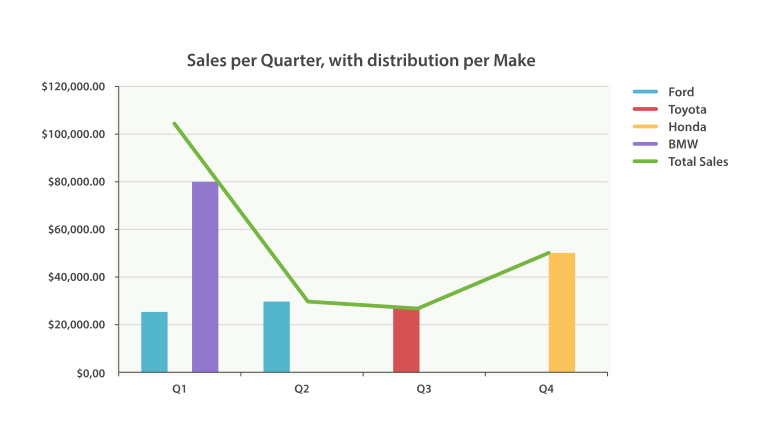
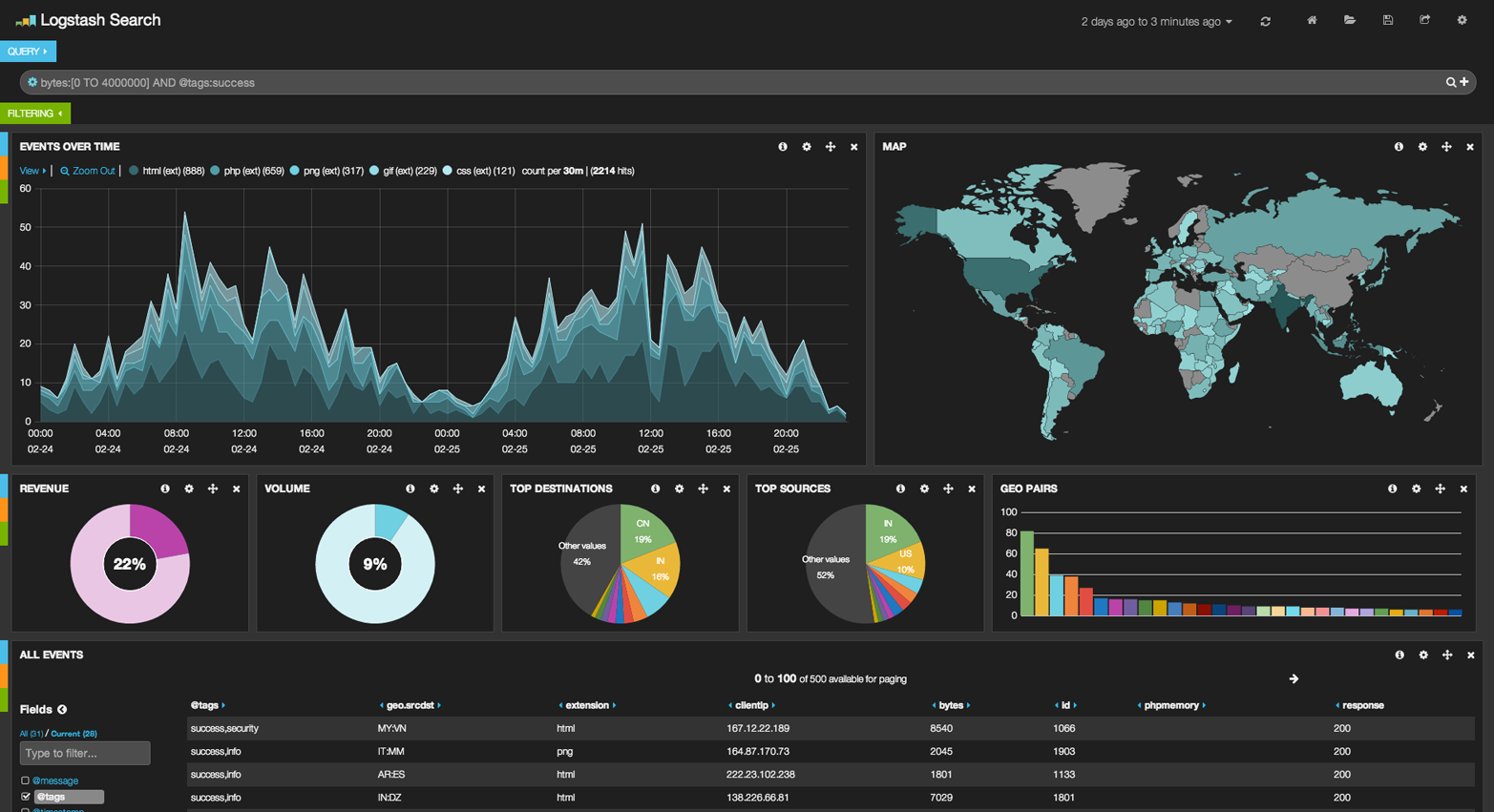
从技术上来讲,是可以的。 通常的 histogram bucket(桶)是可以处理日期的。 但是它不能自动识别日期。 而用 date_histogram ,你可以指定时间段如 1 个月 ,它能聪明地知道 2 月的天数比 12 月少。 date_histogram 还具有另外一个优势,即能合理地处理时区,这可以使你用客户端的时区进行图标定制,而不是用服务器端时区。
通常的 histogram 会把日期看做是数字,这意味着你必须以微秒为单位指明时间间隔。另外聚合并不知道日历时间间隔,使得它对于日期而言几乎没什么用处。